Vodafone April 2026: Abschlussbericht nach 201 Stunden
Der zweite Vodafone-Ausfall im April ist vorbei — nach 8 Tagen und 9 Stunden. Mit vollständiger Datenanalyse, einem Rückblick auf den chaotischen Verlauf und einem klaren Urteil.
- Schlagworte
- #Internet #Vodafone #Störung #Monitoring #Homelab #FRITZ!Box
- veröffentlicht
- Lesezeit
- 4 Minuten
Heute um 13:00 Uhr kam die erste Stunde zurück, in der alle Tests grün waren. 43 Millisekunden. Null Fehler. Zwölf von zwölf.
Es ist vorbei.
“8 Tage. 9 Stunden. 201 Stunden Vodafone-Kabel-Ausfall am Stück.”
Ich schreib das auf, bevor ich es irgendwie rationalisiere oder vergesse. Das war kein normales Netzproblem. Das war eine der auffälligsten Infrastruktur-Katastrophen, die ich in Jahren als Privatkunde erlebt habe — und ich habe Monitoring-Daten, die jede einzelne Stunde dokumentieren.
Was die Daten wirklich zeigen
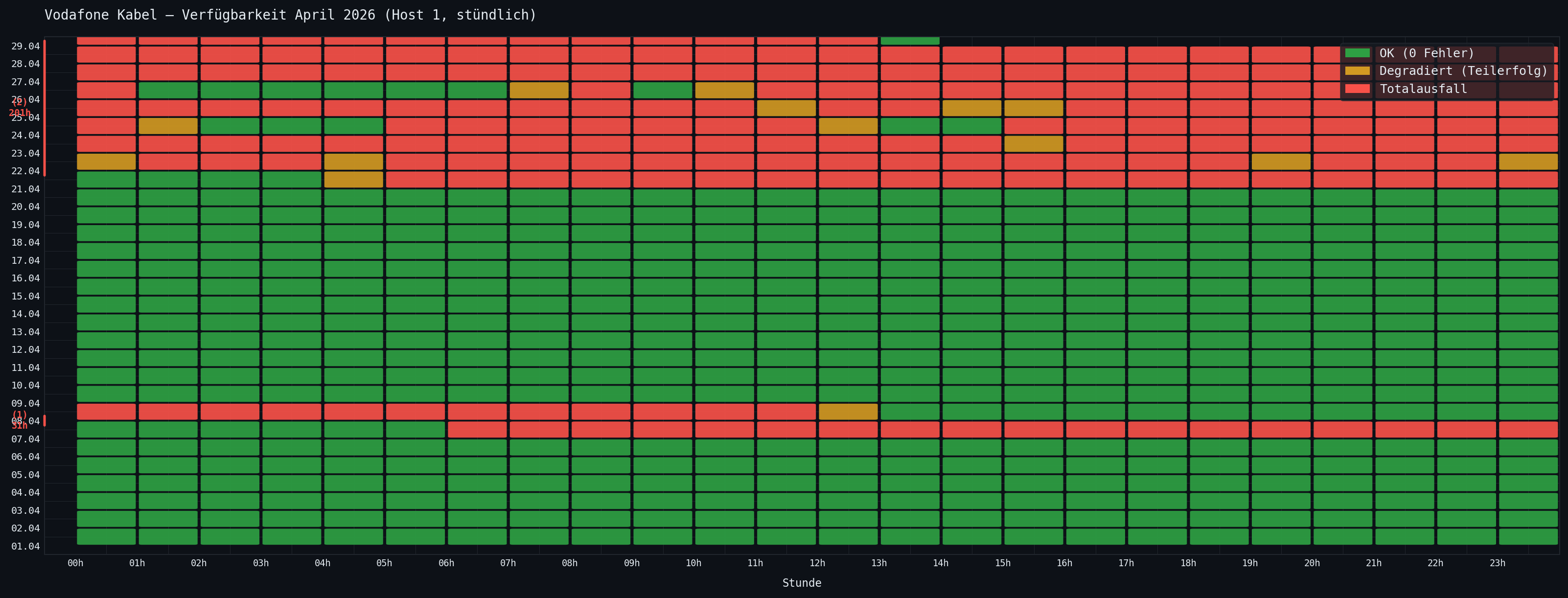
Zum Kontext: Ich messe meinen Anschluss seit längerem stündlich mit automatisierten Tests gegen externe Endpunkte. Aus dieser Tabelle lässt sich der gesamte April 2026 rekonstruieren.
Erster Ausfall: 07.–08. April
Start: 07.04. um 06h, Ende: 08.04. um 13h — klassischer Totalausfall. Antwortzeiten um die 10.000 ms (Timeout), 0 erfolgreiche Tests, stundenlang ohne jede Bewegung.
Einzige Ausnahme: 07.04. 13h — ein einziger erfolgreicher Test von elf. Kurzes Flackern, dann wieder weg.
Gesamtdauer erster Ausfall: 31,5 Stunden.
Zwölf ruhige Tage
Vom 09.04. bis 20.04. war der Anschluss stabil. Latenzen zwischen 34 und 53 ms, keine Fehler. Einzige Auffälligkeit: 16.04. um 17h mit 518 ms Durchschnittslatenz — kein Ausfall, aber spürbar träge. Ich hab’s kurz im Blick gehabt und dann abgehakt.
Zweiter Ausfall: 21.–29. April
Start: 21.04. um 04h. Wie beim ersten Mal: mitten in der Nacht, langsam anlaufend.
| Zeitpunkt | Situation |
|---|---|
| 21.04. 03h | Letzte stabile Stunde (47 ms, 0 Fehler) |
| 21.04. 04h | Degradierung beginnt (9 OK, 3 Fehler, 2.536 ms) |
| 21.04. 05h | Fast komplett weg (1 OK, 10 Fehler, 9.902 ms) |
| 21.04. 06h | Totalausfall |
| 22.–23.04. | Chaotisches Flackern — mal 5/12, mal 13/14 Tests OK |
| 24.04. 02–04h | Drei echte Stunden Verbindung (~40 ms, 12/12 OK) |
| 24.04. 05h | Wieder weg |
| 25.–28.04. | Nahezu vollständiger Dauertotalausfall |
| 26.04. 01–06h | Kurzes Fenster mit stabiler Verbindung |
| 26.04. 09h | Eine gute Stunde, dann wieder weg |
| 29.04. 00–12h | Volltotalausfall |
| 29.04. 13h | Wiederherstellung |
Gesamtdauer zweiter Ausfall: 201 Stunden — 8 Tage und 9 Stunden.
Was diesen Ausfall so anstrengend gemacht hat
Beim ersten Ausfall war die Situation wenigstens klar: alles down, man wartet. Unangenehm, aber eindeutig.
Dieser Ausfall war anders. Die kurzen Fenster — 24.04. morgens, 26.04. früh — haben mich jedes Mal hoffen lassen, dass es vorbei ist. Und jedes Mal war es nach ein paar Stunden wieder weg. Dreimal aufgetankt an Hoffnung, dreimal wieder leer.
Das riecht immer noch nach einem instabilen Signal im Kabelnetz — etwas, das sich unter Last stabilisiert, dann wegbricht, kurz erholt und wieder einbricht. Kein einfacher Kabelbruch. Das ist schwer zu lokalisieren und offensichtlich schwer zu beheben.
Für mich als Kunden: eine der frustrierendsten Fehlermuster überhaupt.
Der Failover hat funktioniert — mit Einschränkungen
Die FRITZ!Box 6860 5G als Fallback hinter der FRITZ!Box 6690 Cable war die richtige Entscheidung. Homelab, NAS, Proxmox und SmartHome haben die meiste Zeit des Ausfalls überlebt. Das war im vorherigen Beitrag bereits das Thema.
Was ich seitdem noch beobachtet habe: Der Monitoring-Datensatz oben zeigt die Primärverbindung — also Vodafone Kabel direkt. Die kurzen Stabilitätsfenster (24.04., 26.04.) sieht man dort, weil ich zwischen beiden Anschlüssen messe.
Was noch nicht rund ist: die Failover-Wechselzeiten. Es gibt kurze Lücken, wenn die 6690 den Kabelausfall erkennt und die 6860 die 5G-Einwahl aufbaut. Für normale Nutzung kaum spürbar — für laufende SSH-Sessions und VPN-Tunnels schon. Das ist das nächste Projekt.
Fazit: Was bleibt
Vodafone hat in diesem Monat zweimal meinen Anschluss lahmgelegt. Einmal für 31,5 Stunden, einmal für 201 Stunden. Zusammen sind das 232 Stunden ohne zuverlässige Kabelverbindung — fast 10 Tage im April.
Kommunikation dazu? Keine, die ich als Privatkunde proaktiv erhalten hätte.
Ob das die gleiche Ursache war, die nie richtig behoben wurde? Ich weiß es nicht. Die Signatur war identisch — gleiche Uhrzeit des Beginns, gleiche Timeouts, gleicher chaotische Charakter beim zweiten Mal. Ich kann nur spekulieren.
Was ich nicht mehr spekulieren muss: Ein Single-Point-of-Failure beim Internetanschluss macht für ein Homelab keinen Sinn. Das hat dieser Monat endgültig bewiesen. Der Failover bleibt. Und die Monitoring-Daten auch.
Schön wäre es, wenn man das alles nicht bräuchte.
Bleibt neugierig,
Alex